
어느덧 Apache Spark 관련 포스트로 5개의 글이 작성되었다. 이전 포스트에서는 PySpark로 DataFrame을 다루는 기초에 대해 확인했다면, 이번 포스트부터는 본격적으로 머신러닝을 위한 활용단계이다.
❗️강의에 들어가기에 앞서❗️
현재 PySpark를 실행한 환경은 다음과 같다.
- os : Linux Ubuntu (맥북에서 utm으로 linux 가상환경 생성)
- ram : 8gb (맥북 16gb 램에서 절반인 8gb할당)
- hdd : 25gb
- ubuntu ver : 22.04.5
- spark ver : spark-3.5.6
- python ver : 3.10
1️⃣ 라이브러리 불러오기
✅ 기본 라이브러리 불러오기
# spark 설치 경로 찾기
import findspark
findspark.init('/home/dalleeoppaa/spark-3.5.6-bin-hadoop3') # 본인의 경로에 맞게 설정
# spark 세션 불러오기
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('lrex').getOrCreate()✅ 선형회귀 모델 불러오기
from pyspark.ml.regression import LinearRegression- 일반적인 Pandas에서의 머신러닝 모델을 불러올 때는 Scikit-learn 패키지에서 다양한 모델(ex. `linear_model`, `neighbors` 그리고 대망의 치트키 `ensemble`)을 불러왔다.
- pyspark 에서는 `pyspark.ml.regression`을 통해 `LinearRegression`(선형회귀 모델)을 import 할 수 있다.
2️⃣ 데이터 불러오기


- 데이터는 udemy pyspark 빅데이터 강의에서 제공되는 임의로 제작된 데이터를 사용했다.
3️⃣ 데이터 나누기
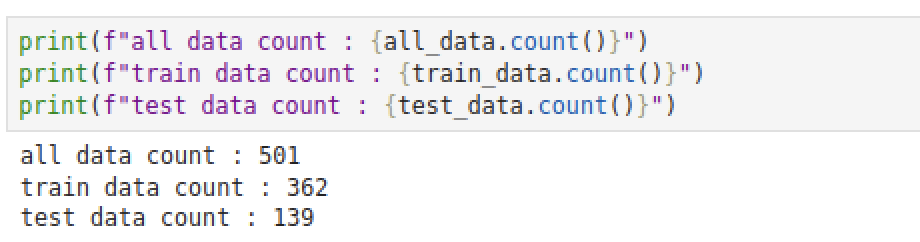
train_data, test_data = all_data.randomSplit([0.7, 0.3])- 훈련/테스트 데이터의 비율을 7:3으로 나눈다.
- 데이터가 잘 나눠졌는지 간단하게 확인해보자.
4️⃣ 선형회귀 모델 생성
lr = LinearRegression(featuresCol='features', labelCol='label', predictionCol='prediction')
- Estimator 객체 생성
- 해당 단계에서는 알고리즘 종류, 입력 컬럼명, 타겟 컬럼명, 하이퍼 파라미터 등의 설정만 정의한다.
lrModel = lr.fit(train_data)- 생성한 선형회귀 모델을 train_data 데이터셋으로 훈련시킨다.
- scikit-learn 방식과 매우매우 비슷하다.
5️⃣ test 데이터 예측하기
test_results = lrModel.evaluate(test_data)- `모델명.evaluate(test 데이터셋)` 으로 예측 결과를 생성한다.
6️⃣ 모델 파라미터 확인
# 회귀 계수 확인
lrmodel.coefficients
# 절편 확인
lrmodel.intercept
7️⃣ 모델 회귀 지표 확인
# 모델 예측 결과 확인
test_summary = lrModel.summary
# r2 (결정계수) 확인
test_summary.r2
# RMSE (평균 제곱은 오차) 확인
test_summary.rootMeanSquaredError
# MSE (평균 제곱 오차) 확인
test_summary.meanSquaredError8️⃣ 예측 결과 라벨링
# 테스트에 사용된 피쳐만 추출
unlabeled_data = test_data.select('features')
# 모델 예측 결과를 변환
predictions = lrModel.transform(unlabeled_data)

전체적으로 scikit-learn에서 머신러닝 모델 생성-학습-예측-지표확인 단계가 비슷하게 진행된다.
다음 포스트는 이제 분류모델이 되지 않을까 싶다...??
'데이터분석 > 04. Apach Spark' 카테고리의 다른 글
| [Spark] 07. PySpark로 Logistic Regression(로지스틱회귀분석) 모델 만들기 (0) | 2025.09.13 |
|---|---|
| [Spark] 05. PySpark DataFrame 기초 연습 (0) | 2025.09.12 |
| [Spark] 04. Ubuntu에 python, jupyter notebook, spark 설치해보기 (0) | 2025.09.10 |
| [Spark] 03. 맥북 M1에 UTM으로 우분투 arm64 설치하기 (1) | 2025.09.09 |
| [Spark] 02. Pyspark 예제 데이터로 기초 실습(feat. EDA) (0) | 2025.09.08 |