
udemy 에서 pyspark 로 빅데이터 분석하기 with python 강의를 들은지 어느덧 2일차가 되었다.
1일차는 사실상 설치하고 실행하는데 끝나버렸고, 2일차인 오늘부터 제대로 된 pyspark를 활용한 dataframe 다루기를 해봤다.
❗️강의에 들어가기에 앞서❗️
현재 PySpark를 실행한 환경은 다음과 같다.
- os : Linux Ubuntu (맥북에서 utm으로 linux 가상환경 생성)
- ram : 8gb (맥북 16gb 램에서 절반인 8gb할당)
- hdd : 25gb
- ubuntu ver : 22.04.5
- spark ver : spark-3.5.6
- python ver : 3.10
1️⃣ PySpark 불러오기
# findspark 로 spark 경로 잡아주기
import findspark
findspark.init('아파치 스파크 폴더 경로')- 간단하게 다운받은 스파크 폴더 경로를 지정해주면 된다.
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('세션 이름설정').getOrCreate()- PySpark 실행을 위해 이름을 지정하고, Spark 세션을 생성해준다.
2️⃣ 데이터 불러오기
df = spark.read.csv('appl_stock.csv', inferSchema=True, header=True)- `inferSchema` : pyspark 에서 csv 파일을 읽을 때, 각 컬럼의 데이터 타입을 자동으로 추론하는 옵션
- `inferSchema=True` : 데이터를 스캔해서 숫자는 IntegerType/DoubleType, 날짜는 TimestampType 등으로 변환
- `inferSchema=False` : 모든 컬럼을 문자열 StringType 으로 읽음
3️⃣ 데이터 스키마, 예시 등 기초 확인하기
✅ 데이터 예시 확인하기
# 전체 데이터 확인해보기
df.show()
# 특정 컬럼만 확인해보기
df.select(['컬럼명1', '컬럼명2']).show()
✅ 데이터 스키마 확인하기
df.printSchema()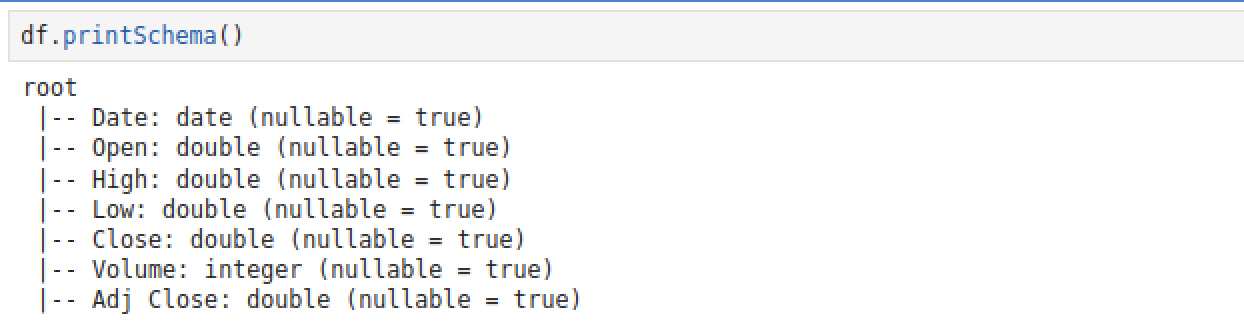
4️⃣ 조건을 걸어서 데이터 확인하기
# Close 컬럼이 500 미만일 때, Open, Close 컬럼만 보기
df.filter('Close < 500').select(['Open', 'Close']).show()
# 혹은 이렇게 써도 상관 없다
df.filter(df['Close'] < 500).select(['Open', 'Close']).show()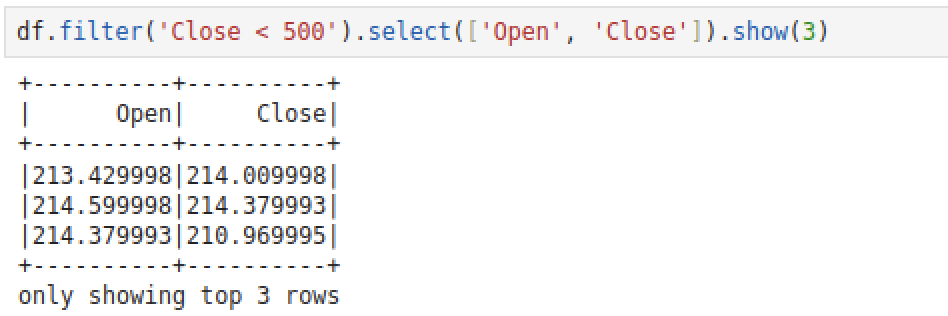
# 두 가지 이상의 조건이 있을 때
df.filter((df['Close'] < 200) | (df['Open'] > 100)).show()5️⃣ 새로운 컬럼 생성
df.withColumn('double_age', df['age']*2).show()- `withColumn` : 새로운 컬럼을 생성하고 싶을 때 사용, withColumn('컬럼명', 생성될 컬럼 정보)
6️⃣ 컬럼명 변경
df.withColumnRenamed('age', 'my_new_age').show()- `withColumnRenamed` : 컬럼명을 변경할 때 사용, withColumnRenamed('변경할 컬럼명', '새로운 컬럼명')
7️⃣ 다양한 함수
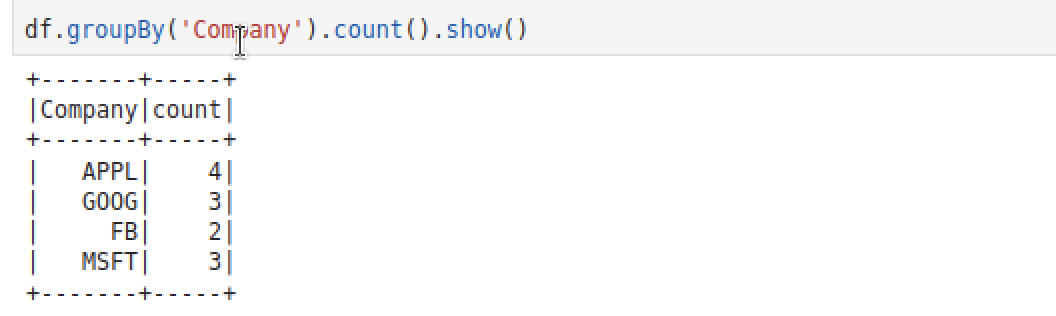
df.groupBy('Company').count().show()- `groupBy` : 특정 컬럼을 기준으로 그룹핑
- `count()` : 특정 컬럼에 있는 값의 개수 카운트
8️⃣ 정렬
# 오름차순
df.orderBy('Sales').show()
# 내림차순
df.orderBy(df['Sales'].desc()).show()

다음 포스트에서는 Apache Spark 에서 제공하는 MLlib 에 대해서 포스트 할 예정이다!
'데이터분석 > 04. Apach Spark' 카테고리의 다른 글
| [Spark] 07. PySpark로 Logistic Regression(로지스틱회귀분석) 모델 만들기 (0) | 2025.09.13 |
|---|---|
| [Spark] 06. PySpark로 Linear Regression(선형회귀) 모델 만들기 (0) | 2025.09.12 |
| [Spark] 04. Ubuntu에 python, jupyter notebook, spark 설치해보기 (0) | 2025.09.10 |
| [Spark] 03. 맥북 M1에 UTM으로 우분투 arm64 설치하기 (1) | 2025.09.09 |
| [Spark] 02. Pyspark 예제 데이터로 기초 실습(feat. EDA) (0) | 2025.09.08 |