
2025.09.09 - [데이터분석/04. Apach Spark] - [Spark] 03. 맥북 M1에 UTM으로 우분투 arm64 설치하기
[Spark] 03. 맥북 M1에 UTM으로 우분투 arm64 설치하기
이전 포스트에서는 docker에 PySpark/Jupyter-notebook를 올려서 PySpark를 사용했으나..2025.09.08 - [데이터분석/04. Apach Spark] - [Spark] 02. Pyspark 예제 데이터로 기초 실습(feat. EDA) [Spark] 02. Pyspark 예제 데이터로
dalleeoppaa.tistory.com
이전 글에서 이어집니다!!ㅔ
1️⃣ 파이썬 설치

- 좌측 하단에 Show Applications를 들어가보면 terminal을 찾을 수 있다. terminal을 실행시켜주고

- 터미널에 python을 입력해주면 찾을 수 없다고 나온다.
- python3 으로 입력해주면 3.10.12 버전이 설치되었다고 나오며, 다른 버전을 설치하고 싶으면 아래 명령어를 입력하자
sudo apt install -y software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install -y python3.12 python3.12-venv python3.12-distutils2️⃣ Jupyter Notebook 설치하기
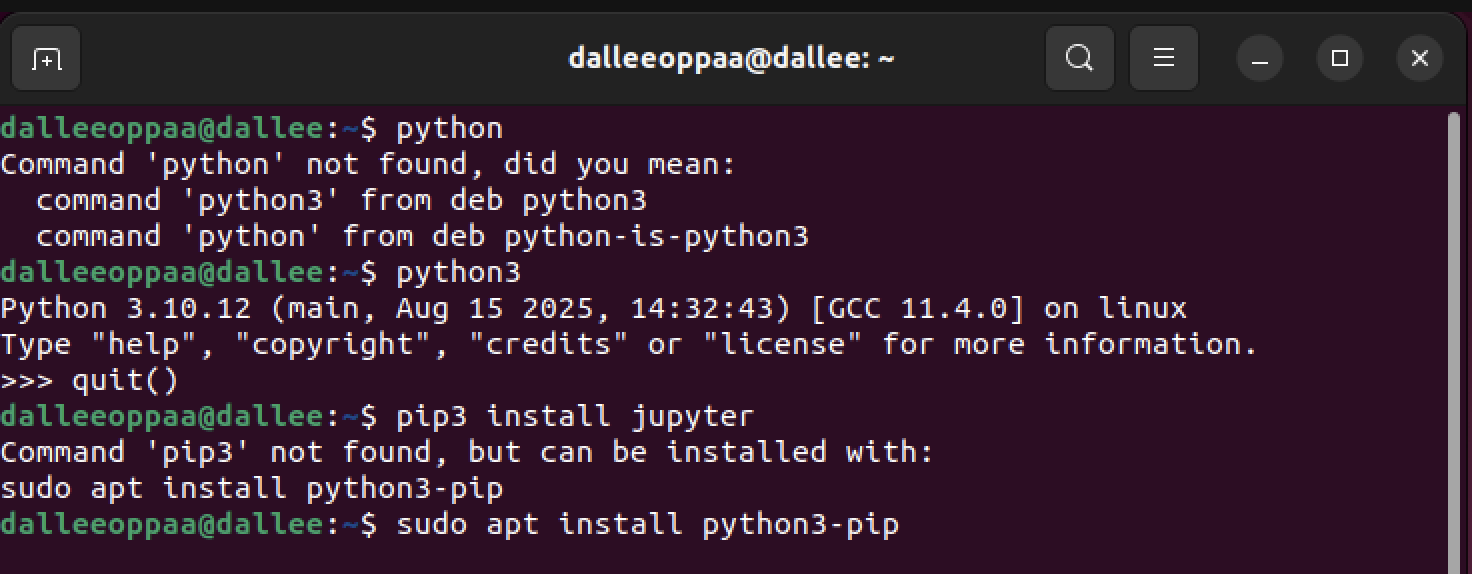
- pip3 install jupyter 명령어를 입력하면 pip이 설치되어 있지 않다고 나온다.
- 아래 명령어들을 차례대로 입력해서 전부 설치를 끝내면 된다
sudo apt install python3-pip
pip3 install jupyter
pip3 install notebook- 이제 주피터노트북을 실행시켜봐야하는데..문제가 생겼다.
- jupyter notebook이 실행이 안되는 현상 발생 > python3 -m notebook 으로 접속 가능
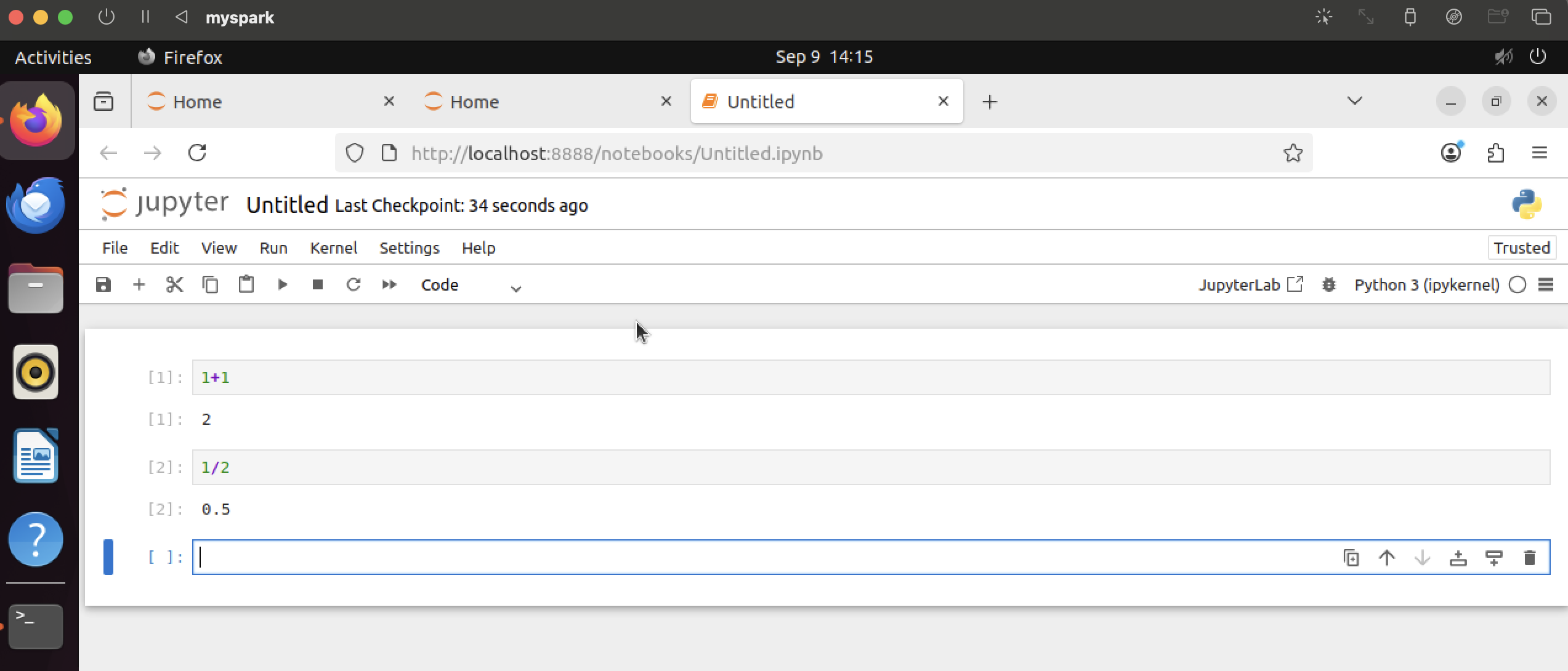
- 노트북 생성해서 간단하게 덧셈 나눗셈 해보니까 잘 되는걸 확인했다ㅎㅎ 이제 python과 Spark를 연결해보자!
- 다시 터미널창에서 ctrl+c 클릭 후 주피터를 off 해놓은 상태로 되돌린다
3️⃣ Spark 설치하기
본격적으로 Spark를 설치하기 전에 미리 설치할 항목이 있다.
✅ Java 설치하기

- sudo apt-get update 로 패키지 관리자를 최신화 해주고
- sudo apt-get install default-jre 로 자바를 설치한다.

- java -version 명령어를 통해 자바가 잘 설치되었는지 확인해보자
✅ scala 설치하기

- 이후 scala 설치를 위해 sudo apt-get install scala 명령어로 설치한다.
- scala 설치가 잘 되었는지 확인하기 위해 scala -version 명령어를 입력해서 확인해본다.
✅ py4j 설치하기

- 이제 자바와 스칼라를 파이썬에 연결해주기 위해 pip3 install py4j 명령어를 입력해서 설치해준다.
- 이제 Spark를 설치해보자
✅ Spark 설치하기

- 파이퍼폭스 창에서 apache spark 검색

- 좌측 상단에 Download 클릭
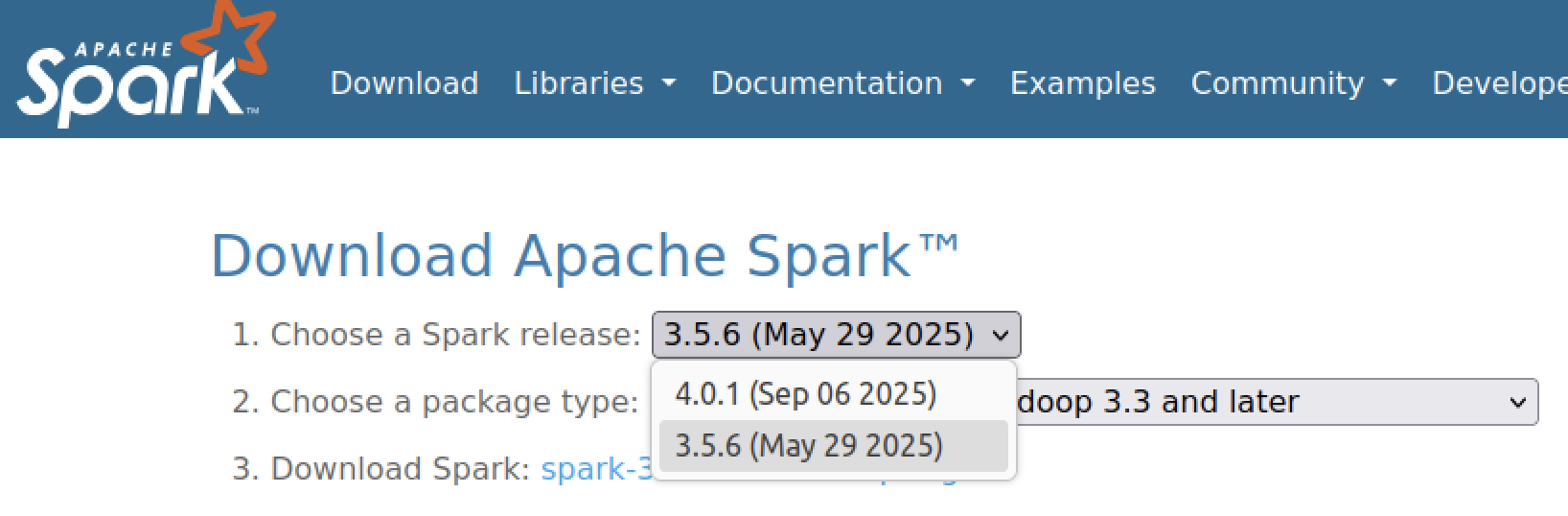
- 가장 최신버전이 4.0.1이지만 나는 안정적인 3.5.6 버전을 선택하겠다.

- 패키지 타입은 Pre-built for Apache Hadoop 3.3 and later 를 선택했다.
- 각 타입에 대한 설명은 다음과 같다.
- Pre-built for Apache Hadoop 3.3 and later → 가장 일반적인 안정 빌드 (Scala 2.12), 대부분의 튜토리얼·실습에 적합.
- Pre-built for Apache Hadoop 3.3 and later (Scala 2.13) → 동일하지만 Scala 2.13 기반, 최신 Scala 프로젝트와 호환성 강화.
- Pre-built with user-provided Apache Hadoop → 직접 설치한 Hadoop 버전에 맞춰 쓰는 고급자용 옵션.
- Source Code → Spark 소스를 직접 빌드해야 하는 개발자·기여자용.
- 이제 download spark 옆에 링크를 클릭해보면

- 아파치 스파크를 다운받을 수 있는 링크가 나온다. 클릭하면 자동 다운로드 되니까 클릭해서 받아주자
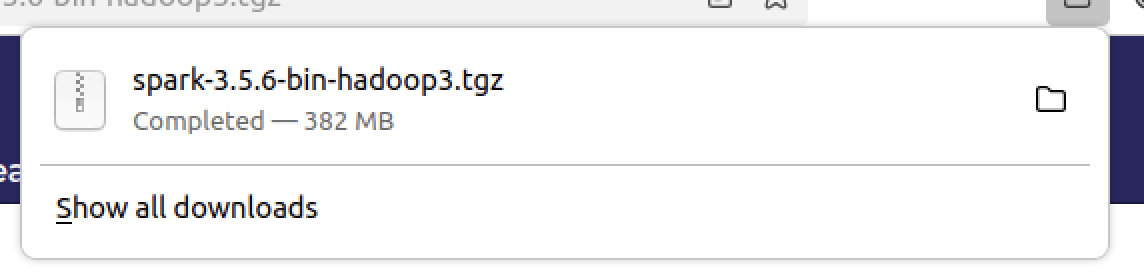

- 이제 다운로드 폴더에 들어가면 받은 파일이 보이는데 우클릭 후 cut 해서 잘래내고 Home 에 붙여넣어주면 된다.


- 붙여넣었다면 다시 터미널로 돌아와서 sudo tar -zxvf spark 를 입력해주고 tab을 클릭하면 방금 home으로 옮긴 tgz 파일이 입력된다. 엔터를 눌러주자

- 이제 아파치 스파크에 환경변수를 설정해줘야 한다.
- export SPARK_HOME='home/ubuntu/spark-3.5.6-bin-hadoop3' : Spark가 설치된 디렉토리 경로 지정
- export PATH=$SPARK_HOME:$PATH : Spark 실행파일 경로를 PATH에 추가
- export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH : PySpark용 Python 모듈을 Python이 찾을 수 있게 추가
- export PYSPARK_DRIVER_PYTHON="jupyter" : PySpark 실행할 때 기본 실행 환경을 Jupyer notebook으로 바꾸는 설정
- export PYSPARK_DRIVER_PYTHON_OPTS="notebook" : 위와 동일
- export PYSPARK_PYTHON=python3 : PySpark가 내부적으로 사용할 인터프리터를 python3로 지정
export SPARK_HOME='home/ubuntu/spark-3.5.6-bin-hadoop3'
export PATH=$SPARK_HOME:$PATH
export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
export PYSPARK_PYTHON=python3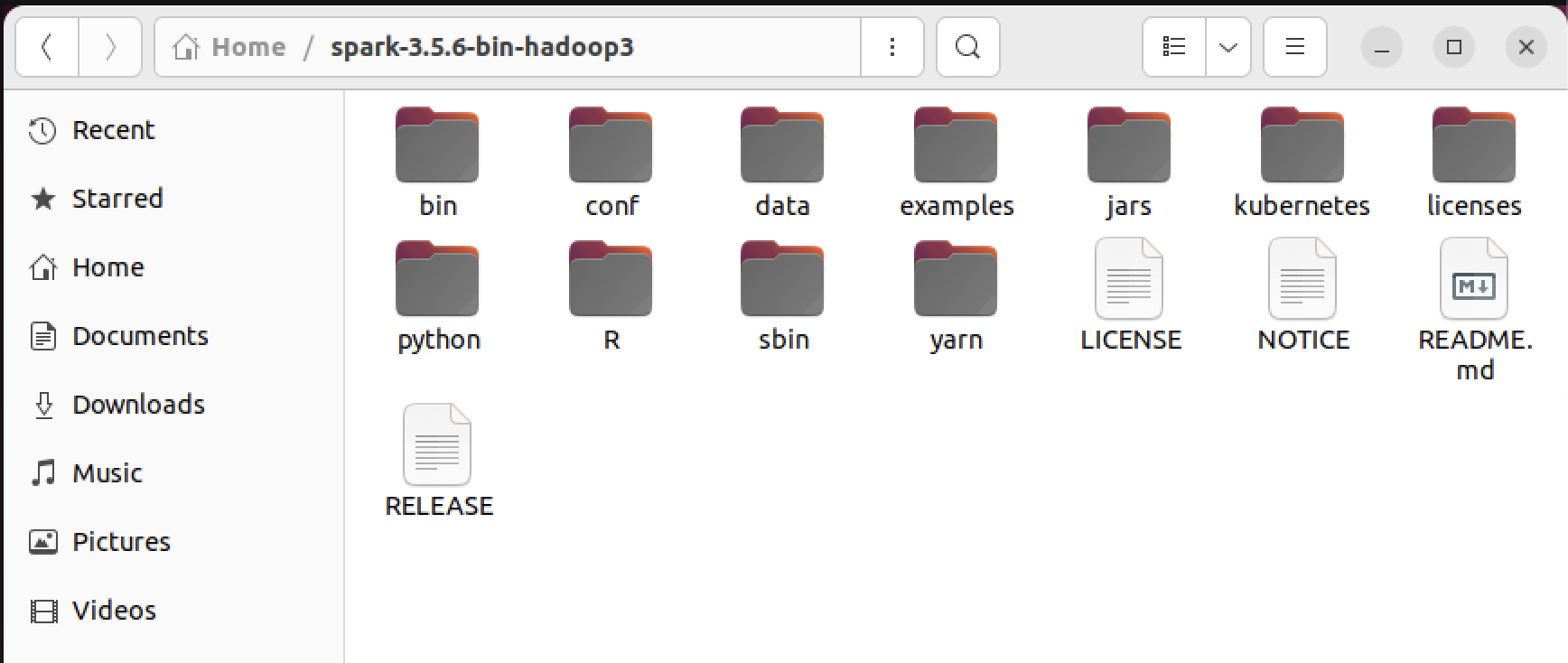
- 이제 PySpark를 주피터로 사용하면서 발생하는 문제점을 잡아보자.
- 먼저 home/spark 폴더 안으로 들어오면 python 폴더가 보인다. 이걸 들어가보면
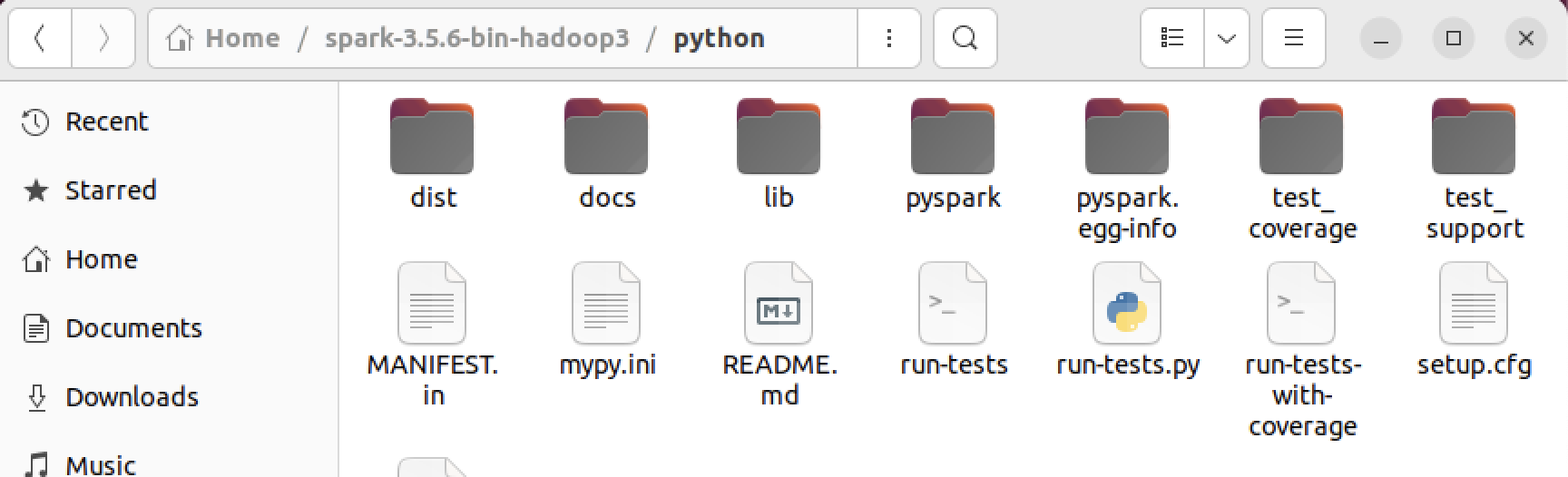
- pyspark 폴더가 보인다. 우린 이제 이 pyspark에 접근할 수 있도록 권한을 허용해줘야 한다.

- chmod 777 spark 입력후 탭을 눌러서 전부 완성시킨 후 엔터를 눌러보면, 변경이 안되었다고 나온다.
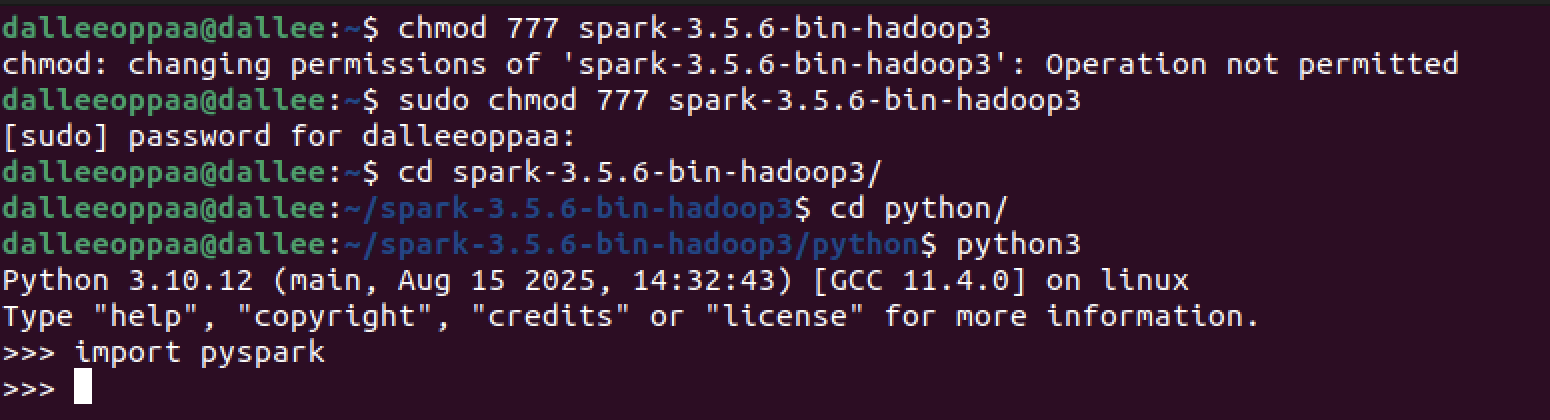
- sudo chmod 777 spark를 이용해서 다시 강제로 변경해준 뒤 비밀번호를 입력해준다.
- 폴더를 spark가 있는 폴더로 이동한뒤 python 폴더까지 들어와준다.
- 이후 python3를 입력해서 버전이 잘 존재하는지 확인 후 import pyspark 실행
- quit()으로 빠져나와주면 된다.
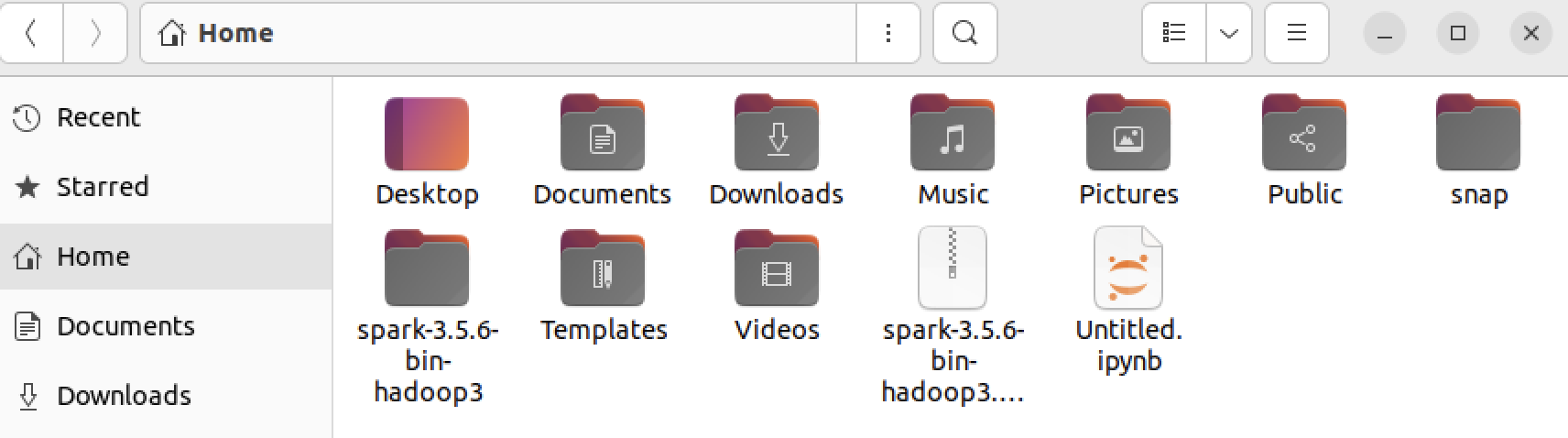
- 이제 홈으로 다시 돌아와보면 spark 폴더에 자물쇠 아이콘이 사라진걸 볼 수 있다!

- 하지만 python과 여러 폴더에는 아직 자물쇠 아이콘이 여전히 존재하는데

- 다시 spark 폴더로 와서 sudo chmod 777 python 을 입력해주면
- python 폴더에 자물쇠 아이콘이 사라진걸 볼 수 있다.
- python 폴더에 들어와보면 아직 pyspark에는 자물쇠가 있는걸 볼 수 있는데 위에 방법과 동일하게 해주면 된다.


- 드디어 pyspark에 걸려있던 락이 해제되었다!

- 이제 노트북에 다시 들어와서 import pyspark 실행해보면 정상적으로 import 해오는걸 볼 수 있다!
끝!!
'데이터분석 > 04. Apach Spark' 카테고리의 다른 글
| [Spark] 06. PySpark로 Linear Regression(선형회귀) 모델 만들기 (0) | 2025.09.12 |
|---|---|
| [Spark] 05. PySpark DataFrame 기초 연습 (0) | 2025.09.12 |
| [Spark] 03. 맥북 M1에 UTM으로 우분투 arm64 설치하기 (1) | 2025.09.09 |
| [Spark] 02. Pyspark 예제 데이터로 기초 실습(feat. EDA) (0) | 2025.09.08 |
| [Spark] 01. GFS와 하둡, 스파크까지 데이터 처리 기술 흐름 (0) | 2025.09.08 |