
오랜만에 하루 2개 포스트를 작성할려니 쉽지 않지만...기록하는 습관을 다시 찾아야 하기 때문에 힘들어도 올려보자!
❓ 기초 실습 개요
1️⃣ 환경 구축
실습환경은 간단하다. Docker에 jupyter/pyspark-notebook 이미지를 띄우고, JupyterLab 환경에서 Pyspark를 실행하는 방식으로 진행했다.
- docker-compose.yml 파일 생성하고, 포트 매핑과 데이터가 저장된 디렉토리를 마운트 설정해줬다.
- JupyterLab 접속, 새로운 노트북 생성, SparkSession을 생성해준다.
- Pandas만 사용하던 때와 다르게, Spark는 SparkSession 이라는 객체를 통해 읽고 처리한다.


2️⃣ 데이터 불러오기
이번 실습에 사용된 데이터셋은 총 두 개의 데이터를 사용했다.
1. MovieLens datasets
- 데이터셋 출처 : GroupLens 연구팀
- 데이터셋 내용 : 영화 추천 시스템 연구를 위해 수집된 데이터셋
- 구성 (ml-latest-small 기준, 약 100,000 ratings)
- movies.csv : 영화 ID, 제목, 장르
- ratings.csv : 사용자 ID, 영화 ID, 평점(0.5~5.0), 타임스탬프
- Docker 컨테이너 안에서 다운로드 진행
# MovieLens "small" 데이터셋 다운로드 (약 1MB)
curl -L -o data/ml-latest-small.zip https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
# 압축 해제
unzip -o data/ml-latest-small.zip -d data/2. NYC Taxi datasets
TLC Trip Record Data - TLC
TLC Trip Record Data Yellow and green taxi trip records include fields capturing pickup and drop-off dates/times, pickup and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. The data used
www.nyc.gov
- 데이터셋 내용 : 뉴욕시에서 운행하는 Yellow Taxi, Green Taxi, For-Hire Vehicle(FHV, 우버·리프트 등) 기록
- 구성 :
- Pickup/Drop-off 시각
- 위치 ID (픽업·하차 Zone)
- 운행 거리 (trip_distance)
- 승객 수 (passenger_count)
- 요금 세부 항목 (기본요금, MTA tax, tip_amount, tolls_amount, congestion_surcharge, etc.)
- 총 요금 (total_amount) 등
- 직접 웹 페이지에 접속 후 parquet 파일 다운로드

3️⃣ MovieLens 평균 평점 확인하기
먼저 데이터를 불러오고 5개 데이터만 확인해보자
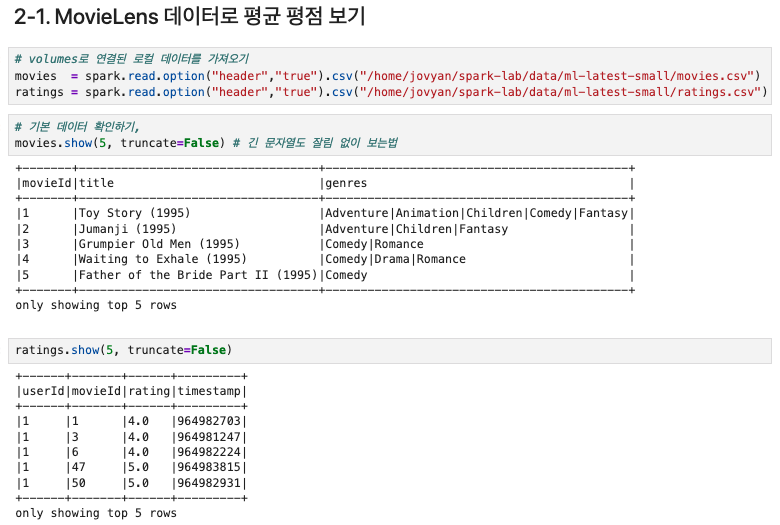
- movies는 movieId 와 title, genres(장르) 가 있고, ratings 는 userId, movieId, rating, timestamp 컬럼이 존재한다.
- 가장 먼저 할 수 있는건 movieId를 기준으로 두 테이블을 조인해서 영화별 평균 평점을 확인 후 평점 상위 10개 타이틀 확인? 정도는 쉽게 할 수 있어보인다.
✅ 평점 상위10 영화 정보 확인하기
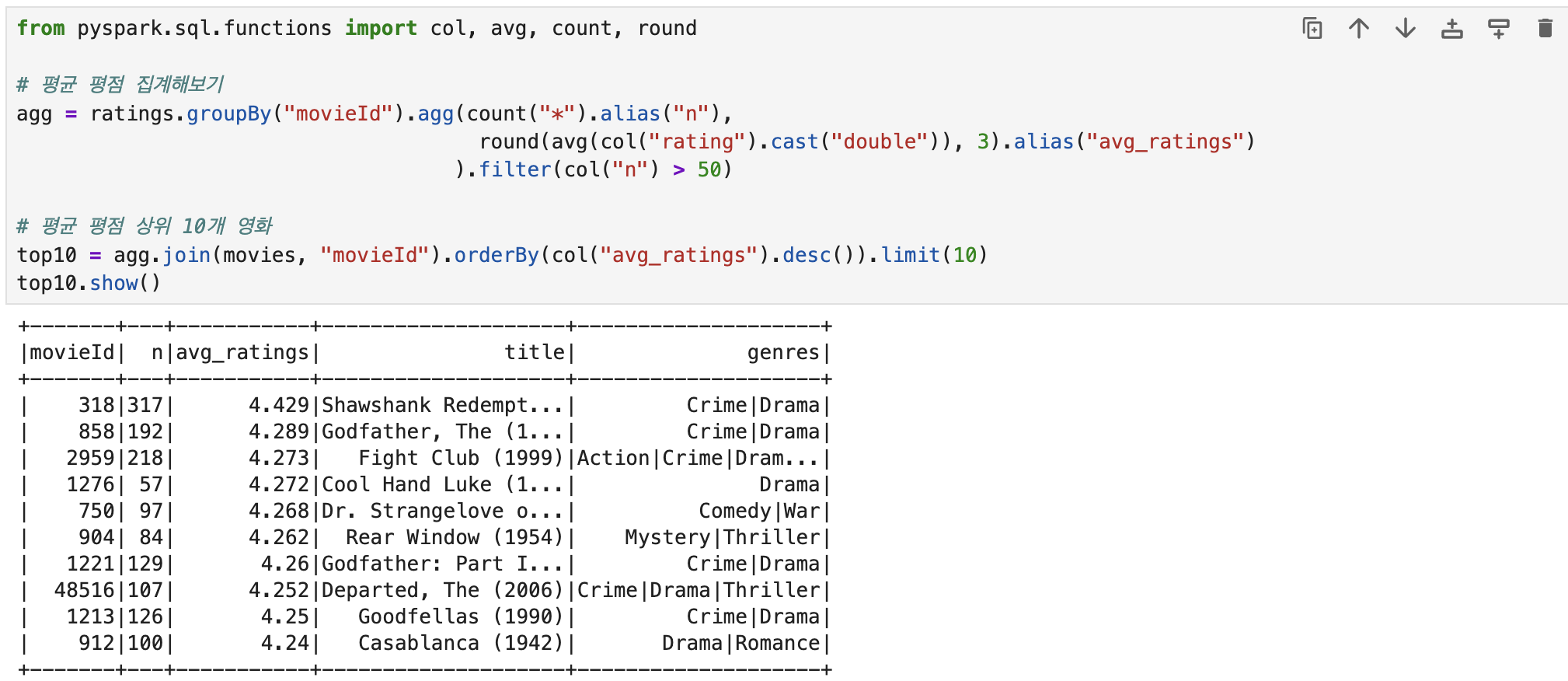
- pandas에서 사용했던 집계함수들을 pyspark에서는 functions에서 불러와줘야 한다. (ex. avg, count, sum, round 등)
- groupBy("movieId") : 영화 제목을 기준으로 그룹화
- count("*").alias("n") : 그룹화 된 데이터들의 개수를 카운트하고 별칭으로 "n"을 붙여줌
- round(avg(col("rating").cast("double")), 3).alias("avg_ratings") : rating 문자열 컬럼을 수치형으로 변환, 평균을 계산하고 반올림해서 소수점 3자리까지 표현하고 별칭은 "avg_ratings"로 설정
- agg.join(movies, "movieId") : 위에서 집계한 데이터와 movies 데이터를 movieId 기준으로 조인
4️⃣ NYC Taxi 데이터 분석하기
컬럼이 너무 많아서 데이터의 스키마 형태를 먼저 파악해보기로 했다.

- lpep_pickup_datetime : 승객이 탑승한 날짜&시간
- lpep_dropoff_datetime : 승객이 하차한 날짜&시간
- fare_amount : 지불금액
- tip_amount : 팁으로 지불한 금액
- cbd_congestion_fee : 보스턴의 혼잡구역을 지날 때 추가되는 금액 (오호..미국 택시는 혼잡비용도 받는구나..)
✅ 간단하게 전처리
데이터를 확인해보니 3월 데이터에 2월 데이터가 조금 섞여있다. 2025. 3. 데이터만 필터링하고 시작하자~

✅ 요일별 이용건수, 평균 요금, 평균 팁 금액 확인해보기


- 1 : 일요일 ~ 7 : 토요일 순서로 보면 된다.
- 일요일이 이용 건 수가 가장 적으며, 월요일에 가장 많은 것을 보니 대부분 월요일에는 피곤해서 택시를 타고 출근해서 그럴 것 같다.
✅ 시간대별로 집계해보기


- 평균 요금(Avg Fare) : 밤 ~ 새벽6시까지 높은 금액이 결제되었는데, 이는 대중교통이 운행을 안하는 시간대라서 택시를 타고 멀리 이동하다보니 평균 요금이 높게 분포되었다고 볼 수 있다.
- 이용 건수(Trips) : 당연히 새벽시간대에 낮게 분포되고, 출근시간대부터 급격히 증가하다가 17시 이후부터 감소하는 경향이 있다.
- 평균 팁(Avg Tip) : 세 개의 데이터를 하나의 그래프에 표현하다보니 차이를 확인하기 어렵지만, 그래도 분석해본다면 새벽시간대에 팁 금액이 높아진다. 아무래도 야간주행&장거리 이동이 있을 수 있어서 팁 금액을 높게 지불하는 것 같다.
✅ 일자별로 집계하기
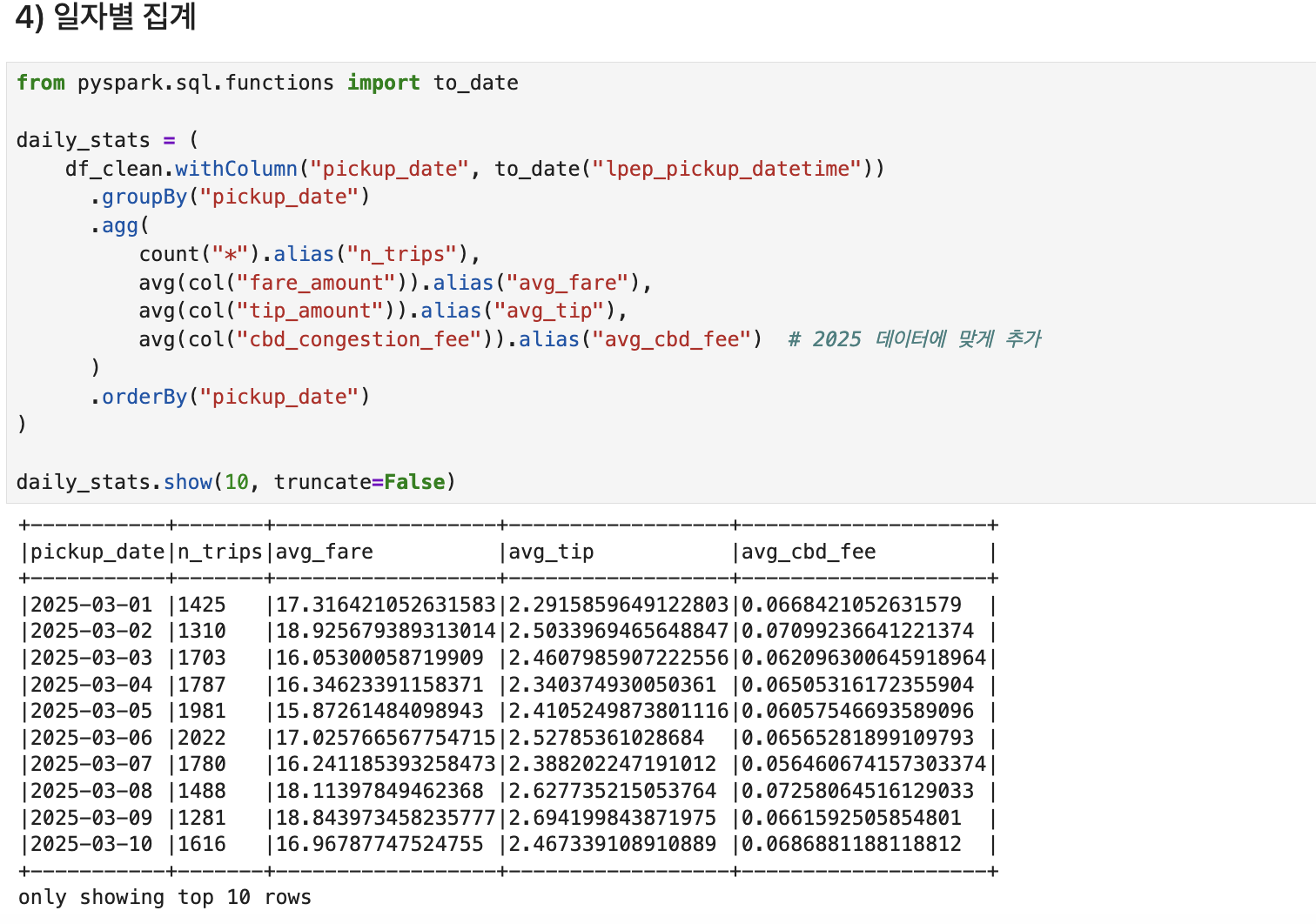

- 주말에는 확연하게 떨어지는 이용건수 패턴을 볼 수 있다.
- 주말일때 평균 지불 요금이 높은 경향을 볼 수 있는데, 아무래도 주말이라는 특수성으로 인해 높은 금액을 받는 것 같다.
기회가 있다면 PySpark 기초를 한번 더 포스트해봐야겠다.. 처음 해보는데 Pandas랑 비슷하다보니 은근 재밌다..
'데이터분석 > 04. Apach Spark' 카테고리의 다른 글
| [Spark] 06. PySpark로 Linear Regression(선형회귀) 모델 만들기 (0) | 2025.09.12 |
|---|---|
| [Spark] 05. PySpark DataFrame 기초 연습 (0) | 2025.09.12 |
| [Spark] 04. Ubuntu에 python, jupyter notebook, spark 설치해보기 (0) | 2025.09.10 |
| [Spark] 03. 맥북 M1에 UTM으로 우분투 arm64 설치하기 (1) | 2025.09.09 |
| [Spark] 01. GFS와 하둡, 스파크까지 데이터 처리 기술 흐름 (0) | 2025.09.08 |